

Dashboard#
openYuanrong provides a visual dashboard for viewing the status of clusters and function instances, facilitating monitoring and quick problem troubleshooting. Currently, the dashboard supports stable loading and display of over a thousand instances.
Starting the Dashboard#
To access the dashboard, you need to add the mode.master.dashboard=true parameter and dependency parameters when deploying the openYuanrong cluster master node. The full deployment command for the master node using all dashboard features is as follows:
# Replace information in {} with actual values
yr start --master \
-s 'mode.master.dashboard=true' \
-s 'mode.master.collector=true' \
-s 'mode.master.frontend=true' \
-s 'function_agent.args.enable_metrics=true' \
-s 'function_agent.args.metrics_config_file="{absolute file path}"' \
-s 'values.dashboard.prometheus.address="{prometheus ip}:{prometheus port}"'
You can refer to the Deployment Parameters Table to trim unnecessary features.
mode.master.frontendparameter provides job information query functionality, affecting the display of job page content.mode.master.collectorparameter provides function instance log collection functionality, affecting the display of log page content.values.dashboard.prometheus.address,function_agent.args.enable_metrics, andfunction_agent.args.metrics_config_fileparameters provide metrics data collection functionality, affecting the display of CPU, Memory, NPU, and Disk items in the Cluster page table. To enable this feature, you need to deploy Prometheus service. Please refer to Deploying Prometheus.
Successful deployment will generate a configuration file /tmp/yr_sessions/latest/dashboard_config with the following content:
{
"ip": "192.168.3.3",
"port": 9080,
...
}
Combine the ip and port as the dashboard access URL: http://192.168.3.3:9080.
Deploying worker nodes, refer to the following command:
# Replace information in {} with actual values
yr start -s 'mode.agent.collector=true' \
-s 'function_agent.args.enable_metrics=true' \
-s 'function_agent.args.metrics_config_file="{absolute file path}"' \
--master_address {http://x.x.x.x:xxxx}
Page Introduction#
The dashboard has multiple pages. View the corresponding page based on functionality:
View total logical resource utilization: Overview Page, Cluster Page
Overview all components and instance status: Overview Page
View status and logical resource utilization of all nodes and components: Cluster Page
View progress and status of all jobs: Jobs Page
View task progress and status of all instances: Instances Page
View and download instance logs and error information: Logs Page
Overview Page#
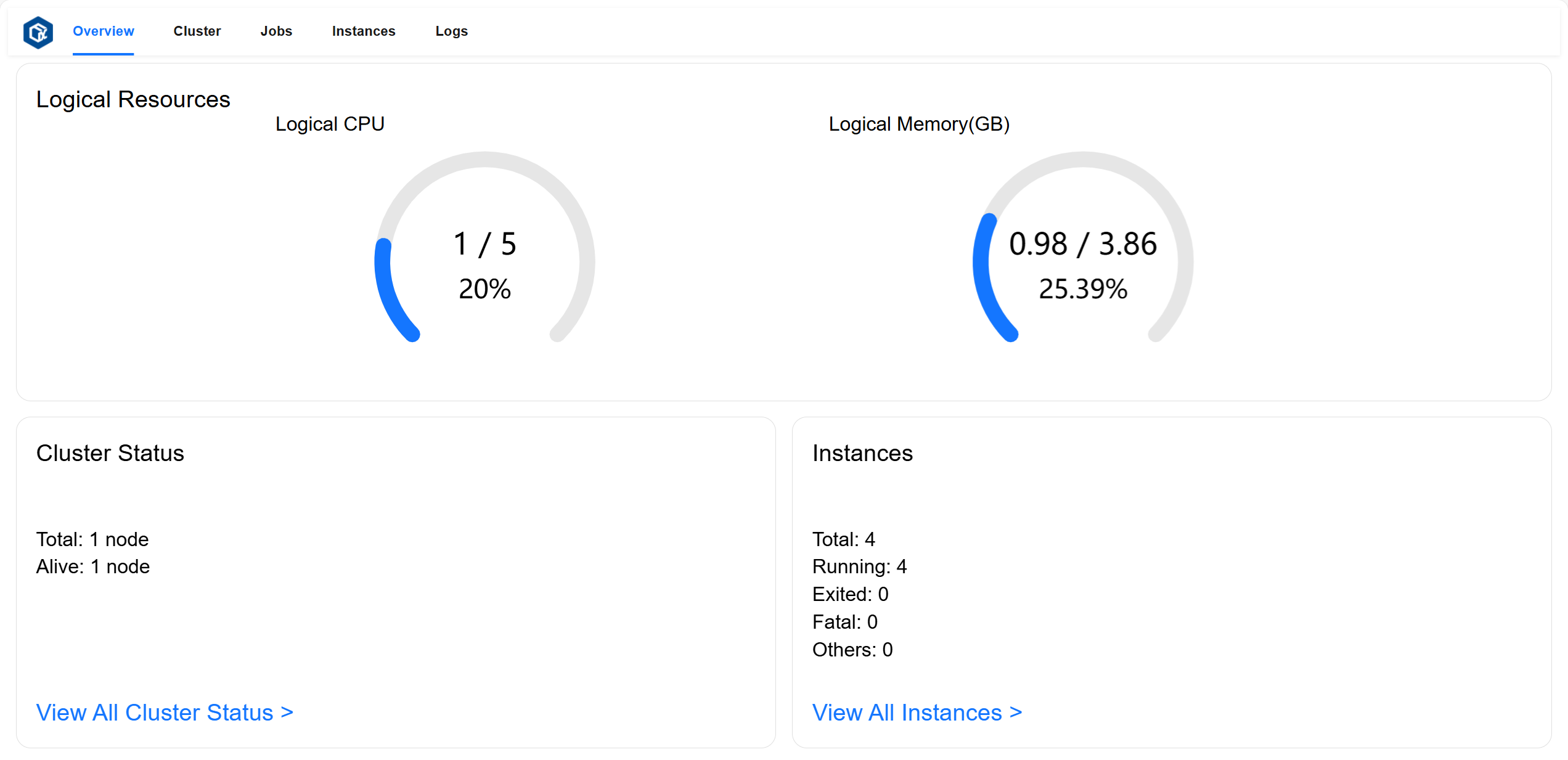
The Overview page allows you to view total logical resource utilization and overview all components and instance status.
Logical Resources card displays total Logical CPU cores used, total cores, and total utilization rate; total Logical Memory used (GB), total memory (GB), and total utilization rate.
Cluster Status card displays total number of nodes and number of active nodes.
Instances card displays total number of instances and number of instances in
running,exited, andfatalstates.
Page example:
Cluster Page#
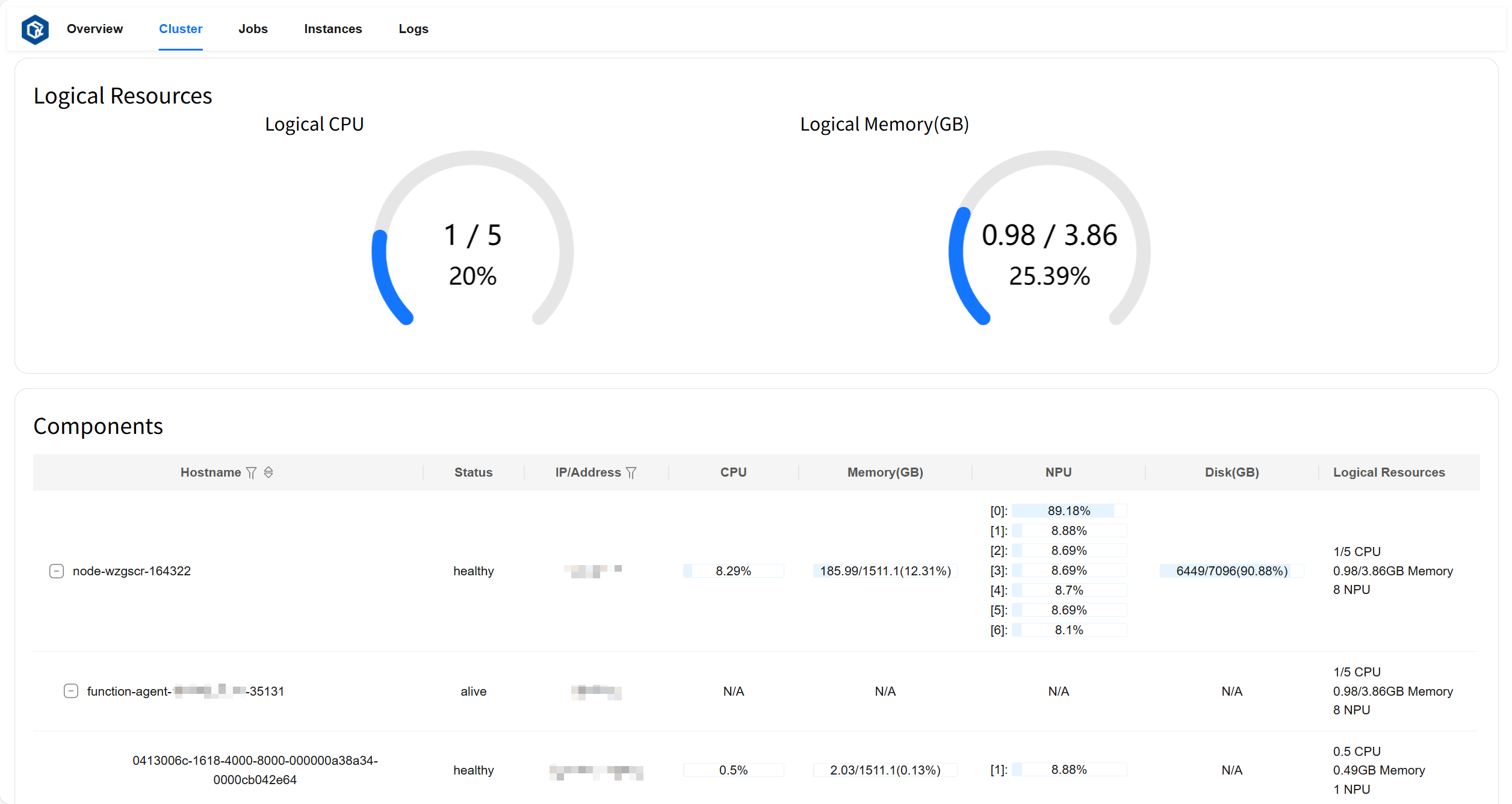
The Cluster page allows you to view total logical resource utilization, status of all nodes and components, resource metrics usage, and visualize the hierarchical relationship between nodes and components.
Logical Resources card displays total Logical CPU cores used, total cores, and total utilization rate; total Logical Memory used (GB), total memory (GB), and total utilization rate.
Components card displays node status, address, CPU and NPU utilization, Memory/Disk/Logical Resources metrics usage, total amount, and utilization rate; agent status running on corresponding nodes, address, Logical Resources metrics usage, total amount, and utilization rate; instance status running on corresponding agents, address, CPU and NPU utilization, Memory/Logical Resources metrics usage, total amount, and utilization rate.
Page example:
Jobs Page#
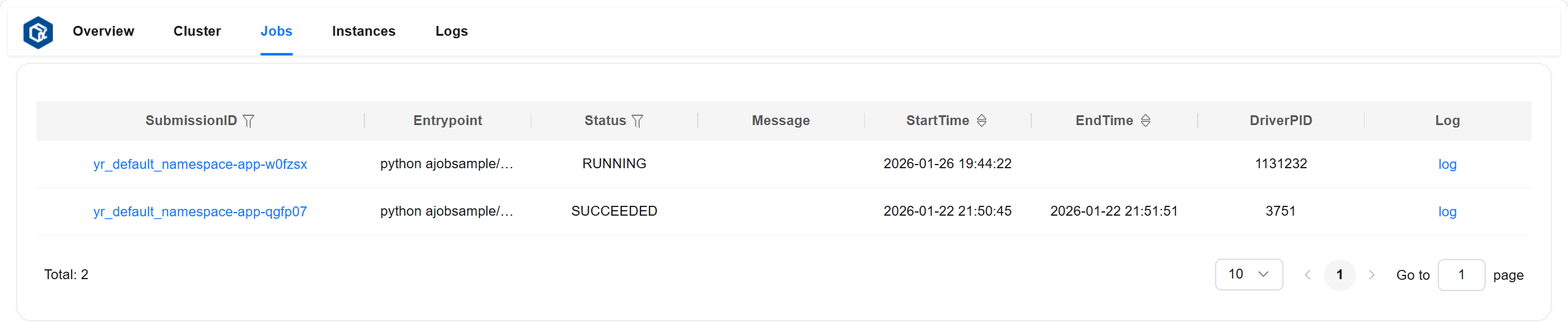
The Jobs page allows you to view detailed information of all jobs.
Job detailed information description:
entrypoint: Job entry command.
runtimeEnv: Job runtime environment.
submissionID: Submission ID when submitting the job.
status: Job status (including: “PENDING”, “RUNNING”, “STOPPED”, “SUCCEEDED”, “FAILED”).
startTime: Job start time.
endTime: Job end time.
message: Detailed information describing job status.
driverNodeID: ID of the node where the job runs.
driverNodeIP: IP of the node where the job runs.
driverPID: PID of the process running the job.
Page example:
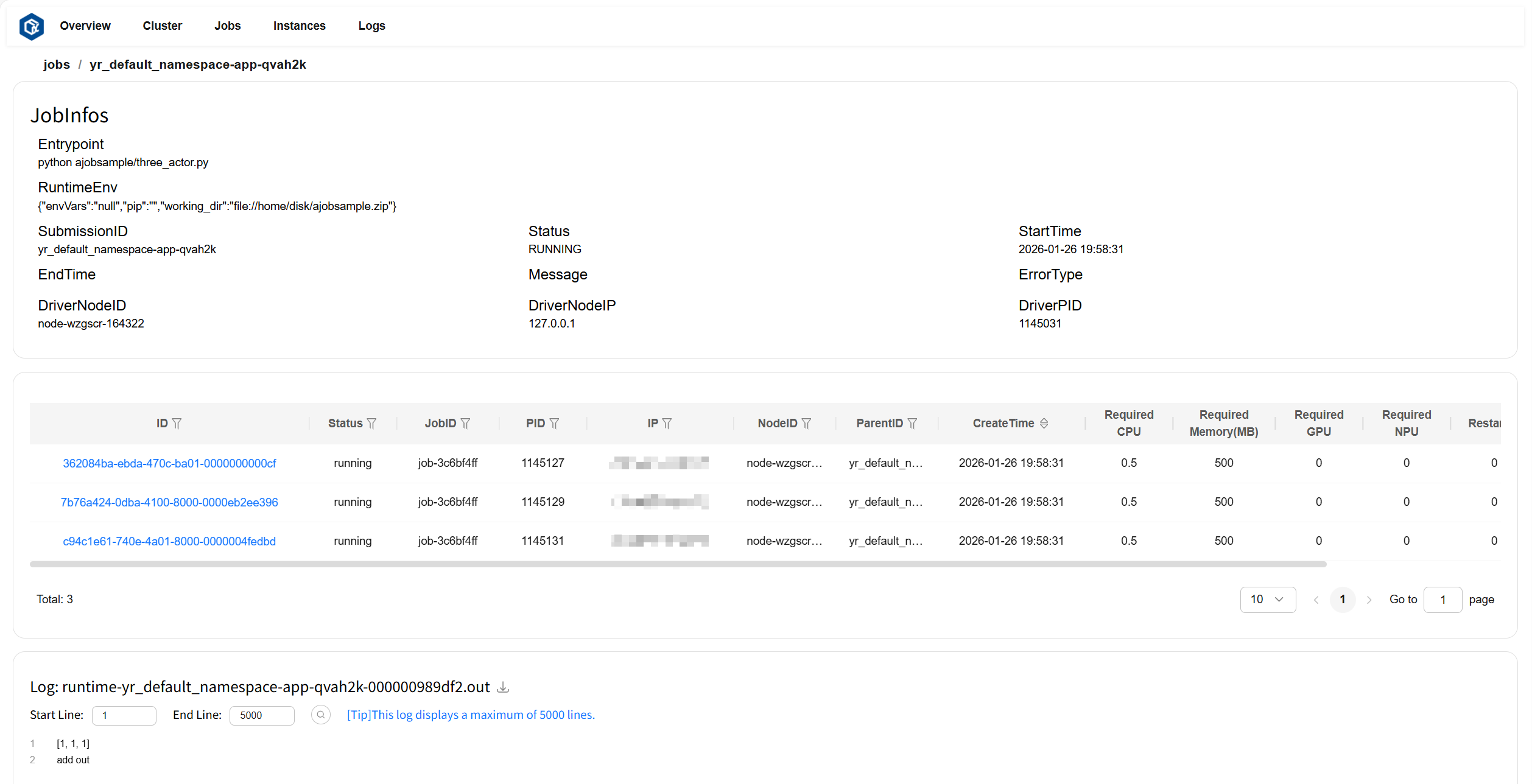
Click SubmissionID or log to navigate to the job details page. The JobInfos card displays detailed information about the job, the instance list card displays instance information contained in the job, and the Log card displays logs and error information for the job.
Page example:
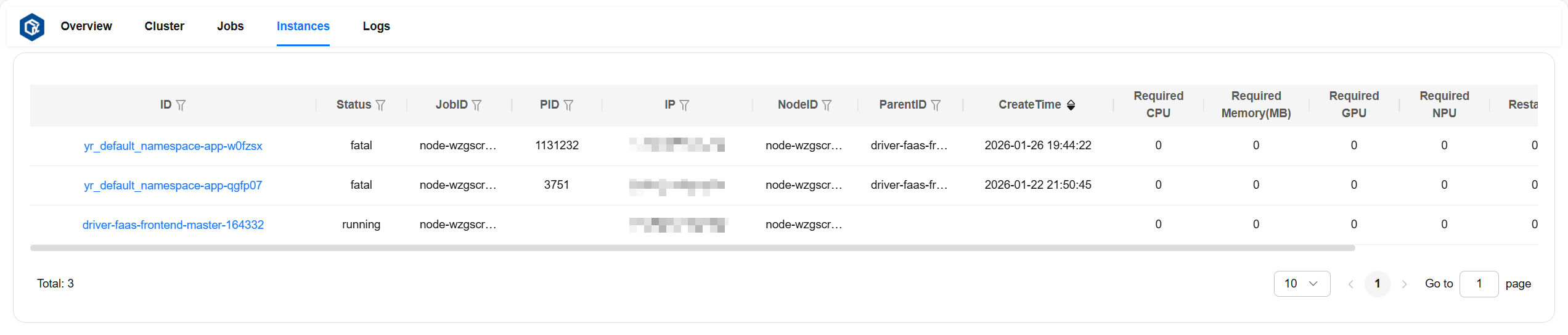
Instances Page#
The Instances page allows you to view detailed information of all instances.
Instance detailed information description:
ID: Instance ID.
status: Instance status.
jobID: ID of the job corresponding to the instance.
PID: PID of the process running the instance.
IP: IP of the node where the instance runs.
nodeID: ID of the node where the instance runs.
parentID: Parent instance ID.
createTime: Instance creation time.
required CPU: Number of CPU cores required by the instance.
required Memory: Memory required by the instance, in MB.
required GPU: Number of GPU cores required by the instance.
required NPU: Number of NPU cores required by the instance.
restarted: Number of instance restarts.
exitDetail: Detailed information when the instance exits.
Page example:
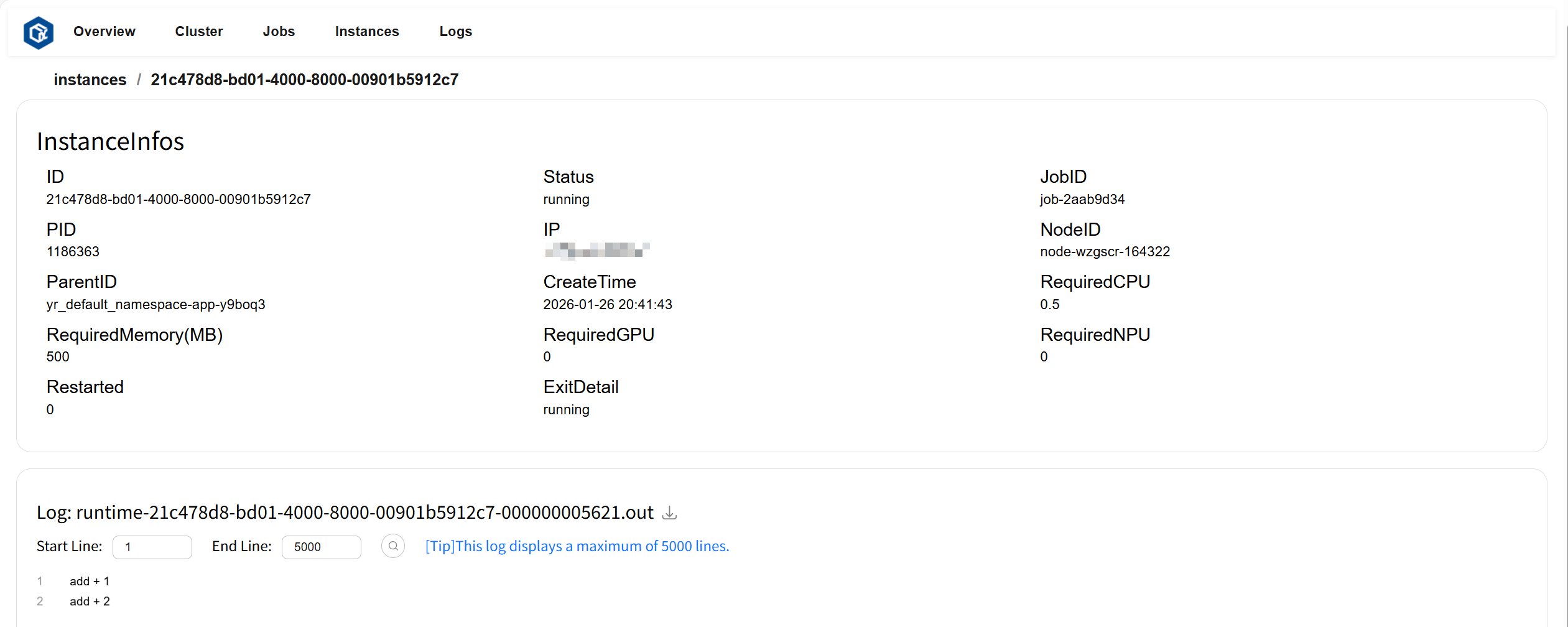
Click ID or log to navigate to the instance details page. The InstanceInfos card displays detailed information about the instance, and the Log card displays logs and error information for the instance.
Page example:
Logs Page#
The Logs page allows you to view and download all log content and error information. Page example:

Click on a selected node to view all log file lists under that node. Page example:
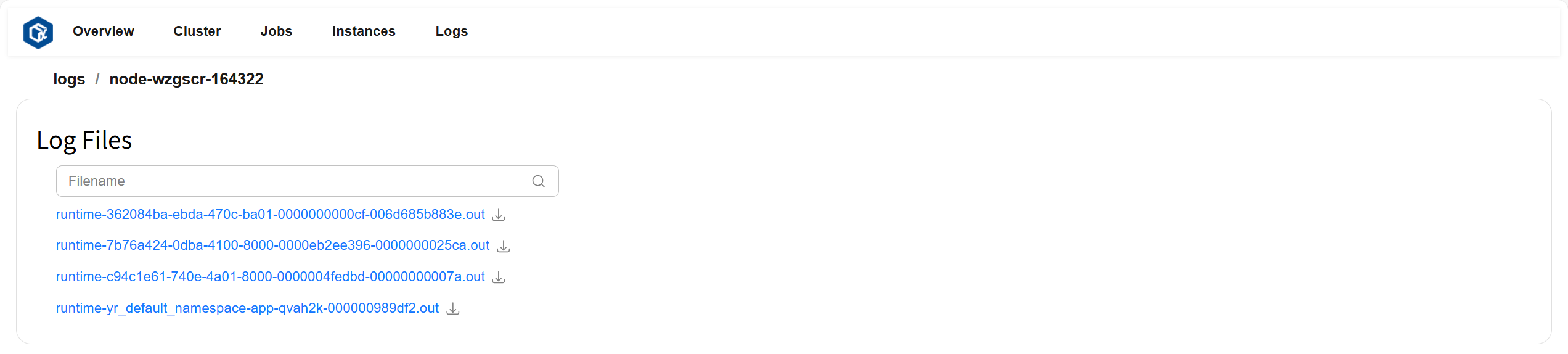
Click on the file you want to view to display the file content. Page example:

Deploying Prometheus#
openYuanrong pushes data to Prometheus through Pushgateway. First, you need to deploy Pushgateway. Download Pushgateway and refer to the following commands to complete the deployment.
tar -xzvf pushgateway-x.xx.x.linux-amd64.tar.gz # Replace tar package name with your downloaded filename
cd pushgateway-x.xx.x.linux-amd64
nohup ./pushgateway > ./pushgateway.log 2>&1 & # Pushgateway default port is 9091
Configuring Prometheus#
Download Prometheus and extract.
tar -xzvf prometheus-x.x.x.linux-amd64.tar.gz # Replace tar package name with your downloaded filename
cd prometheus-x.x.x.linux-amd64
Modify the prometheus.yml file and add the following content in the scrape_configs configuration item, where 127.0.0.1 is replaced with the machine IP running Pushgateway.
- job_name: 'pushgateway'
static_configs:
- targets: ['127.0.0.1:9091']
Starting Prometheus#
nohup ./prometheus > ./prometheus.log 2>&1 & # Prometheus default port is 9090